
2-0.初めに
プログラミング言語のソースコードを実際に動く機械語に変換する方法は無数にあります。古くはC言語で用いられたlexやyaccを使う方法が有名ですが、現在ではコンパイラ作成用に作られた様々なライブラリを利用できます。またオリジナルコンパイラそのものを自動生成してくれるツールすらあります。それらは、便利で信頼性も十分ではありますが、それらを使ってしまうと完全自作の定義から外れてしまいます。ですからここでは全てスクラッチから作ることにしました。
尚、ここに紹介する設計内容はコンパイラ作りのお手本ではありません。コンパイラを自力で作るために無理矢理ひねり出した、信頼性も処理速度も極めて不完全な方法です。もし、貴方がこれから職業としてのコンパイラ屋を目指しているのであれば以下の内容は参考どころか有害となります。多少高価であっても、きちんとしたコンパイル手法の教科書を購入して勉強する事をお奨めします。
2-1. トークン圧縮
このコンテンツを書いている時点では、コンパイルの方法(アルゴリズム)は具体的に決まっていません。「とりあえず作ってみて、ダメだったら修正しよう」程度の考え方で着手しています。その上でまずはトークン情報の圧縮を行う事としました。
| トークン | コード | 補助情報) |
|---|---|---|
| 定数 | N | (その値) |
| アドレス定数 | @ | 変数テーブルのインデクス |
| 変数もしくは関数 | X | 変数テーブルのインデクス |
| レジスタ変数 | R | レジスタ番号 |
| アドレス変数 | A | レジスタ番号 |
| 画像メモリ変数 | P | レジスタ番号 |
| var | D | (なし) |
| if | I | (なし) |
| else | E | (なし) |
| loop | L | (なし) |
| escape | S | (なし) |
| { | { | (なし) |
| } | } | (なし) |
| シフト記号 | > | 右シフトか左シフトか |
| 代入記号 | = | (なし) |
| 比較記号 | ! | 比較種別(6種類) |
| 演算子 | + | 演算種別(7種類) |
| 行番号 | # | 現在処理中の行番号 |
トークン圧縮とは
ここで言うトークン圧縮とは、以下の様なソースコードを、
ver a b if(r0==@a) {b+1} //sample
以下の様に変換することを意味します。
VXXIR!@{X+N}
何やら暗号の様になりましたが、左の表を見ていただければ、変換規則はお判りになると思います。変換後のデータは文字である必要は全くありませんが、デバッグの容易さを考慮して全て文字としました。尚、この時点で不要な空白や改行コード、あるいはコメント等は全て捨てます。
この変換では、定数は何でもNになり、変数は何でもXになってしまいます。これではあとでオブジェクトを生成する際に困りますので、必要に応じて補助情報を持ちます。この補助情報の詳細は別途解説します。
この様に各トークンを一文字に圧縮する事により、後に続く意味解析がとても楽になります。例えば圧縮後の文字列中に X=N という文字の並びがあれば、それは変数に定数を代入するという意味であることを容易に把握できるのです。
現実問題
理論だけなら、バグもトラブルも発生しないので楽しいのですが、現実にはそれを実際に動くプログラムにしなければなりません。全ての設計を終えてからコーディングを始める方法もありますが、個人の趣味の場合は少しずつ動作を確認しながら、設計と実装を追加する方がより現実的です。
そこで、とりあえずテキスト(ソースコード)から圧縮トークン列への変換の実験(検証)を行ないました。
今回はソースコードエディタを作る事自体は目的ではありませんので、ソースコード自体はWindowsの標準APIにあるRichiTextboxに格納します。Qtやeclipseでも同様の事ができますが、今回はVC++の2010Express(無料版)を使ってみました。個人的にはQtやC++Builderの方が好きなのですが、VC++は2008までしか使った経験がなかったので「味見」をした次第です。
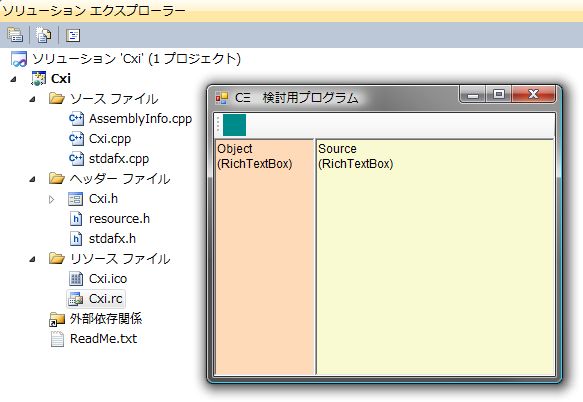 とりあえず RichTextBox を2つ(画像のオレンジ色と黄色の領域)とツールボタン(同、緑色)のみを配置。黄色の領域にソースコードを書き込み、ツールボタンを押下すると、内部の配列に中間コードを格納する。その後内部配列の内容(圧縮トークンコード)を、オレンジ色の領域に表示し、処理が正しいことを確認する方法をとる。
とりあえず RichTextBox を2つ(画像のオレンジ色と黄色の領域)とツールボタン(同、緑色)のみを配置。黄色の領域にソースコードを書き込み、ツールボタンを押下すると、内部の配列に中間コードを格納する。その後内部配列の内容(圧縮トークンコード)を、オレンジ色の領域に表示し、処理が正しいことを確認する方法をとる。
実際のソースコードは、希望する方(twitterもしくはFBで連絡された方)には全て無償公開予定です。 しかし、具体的にいつ、どのような形で公開するかは未定です。(2013/6記)
もうひとつの現実問題は圧縮後のトークンをどの様に保持するかです。
ひと昔前なら「中間ファイル」に格納するのが「常識」でしたが、今回は全てメモリ上に格納する事にしました。このデータは可変長になりますので、具体的にはC++のコンテナを使います。最大でどのぐらいの大きさになるかは不明ですが概算は可能です。ソースコードの文字数(不要な空白やコメントを除く)がオブジェクトのワード数(データ領域は除く)の4倍程度と仮定した場合、RETROF-16の持つ主メモリは64Kワードですので、25万字程度のソースコードが記述できることになります。25万字のソースコードはここでいう「圧縮」を行なうと数分の1になりますが、補助情報が加わりますので結果的に、ソースコードサイズとほぼ同じ大きさになる事が予測できます。
つまり圧縮トークン配列の最大容量は250KB程度です。これはWindowsPCならば、十分にメモリ上に確保できるサイズと判断した次第です。
2-2 C++/CLIによる中間コード生成実装
CΞコンパイラ自身の全ソースは別途公開予定ですので、ここでは中間コードを生成する核となるfor分のみを紹介します。
コンパイルの対象となるソースコードは、RichTetxBoxクラスの変数Src内で管理される1つの巨大なString型の変数です。その長さはSrc->Text->Lengthです。下記のfor分はScanPointer(ソースコードの解析ポインタ、実体は単なる整数)を進めながら、ソースコード全体を中間コードに変換します。変数LineCounterはコンパイラエラーが発生した時にその行番号を把握するための整数です。
下記のコードでは continue を多用していますが、else if 文の羅列でも同じ記述ができます。個人的に else や else if より、continueやbreakの方が好きなので continue を使いました。このあたりはコーディングスタイルに対する好みの問題で深い意味はありません。
for(ScanPointer=0,LineCounter=1; ScanPointer< Src->Text->Length;) {
if (MatchTest(" ")) {/*スキップ*/ continue;}
if (MatchTest("\t")) {/*スキップ*/ continue;}
if (MatchTest("//")) {CommentSkip(); continue;}
if (MatchTest("\n")) {Mid->Put("#",GetLC()); continue;}
if (MatchTest("var")) {Mid->Put("D",NODATA); continue;}
if (MatchTest("if")) {Mid->Put("I",NODATA); continue;}
if (MatchTest("else")) {Mid->Put("E",NODATA); continue;}
if (MatchTest("loop")) {Mid->Put("L",NODATA); continue;}
if (MatchTest("escape")) {Mid->Put("S",NODATA); continue;}
if (HexTest("")) {Mid->Put("N",GetNum()); continue;}
if (NumTest("")) {Mid->Put("N",GetNum()); continue;}
if (HexTest("R")) {Mid->Put("R",GetNum()); continue;}
if (NumTest("R")) {Mid->Put("R",GetNum()); continue;}
if (HexTest("M")) {Mid->Put("M",GetNum()); continue;}
if (NumTest("M")) {Mid->Put("M",GetNum()); continue;}
if (HexTest("V")) {Mid->Put("V",GetNum()); continue;}
if (NumTest("V")) {Mid->Put("V",GetNum()); continue;}
if (MatchTest(">>")) {Mid->Put(">",opSR); continue;}
if (MatchTest("<<")) {Mid->Put(">",opSL); continue;}
if (MatchTest("==")) {Mid->Put("!",opEQ); continue;}
if (MatchTest("!=")) {Mid->Put("!",opNE); continue;}
if (MatchTest(">=")) {Mid->Put("!",opGE); continue;}
if (MatchTest(">")) {Mid->Put("!",opGT); continue;}
if (MatchTest("<=")) {Mid->Put("!",opLE); continue;}
if (MatchTest("<")) {Mid->Put("!",opLT); continue;}
if (MatchTest("++")) {Mid->Put("+",opADC); continue;}
if (MatchTest("+")) {Mid->Put("+",opADD); continue;}
if (MatchTest("--")) {Mid->Put("+",opSBB); continue;}
if (MatchTest("-")) {Mid->Put("+",opSUB); continue;}
if (MatchTest("&")) {Mid->Put("+",opAND); continue;}
if (MatchTest("|")) {Mid->Put("+",opOR) ; continue;}
if (MatchTest("^")) {Mid->Put("+",opXOR); continue;}
if (MatchTest("{")) {Mid->Put("{",NODATA); continue;}
if (MatchTest("}")) {Mid->Put("}",NODATA); continue;}
if (MatchTest("=")) {Mid->Put("=",NODATA); continue;}
if (AdrsTest()) {Mid->Put("@",RegID(GetID())); continue;}
if (VarTest()) {Mid->Put("X",RegID(GetID())); continue;}
/*ここに達するとエラー。とりあえず改行までスキップ */
Mid->Put("?",GetLC()); CommentSkip();
}
左記コード中の関数紹介
MatchTest()
ソースコードのScanPointer(解析ポインタ)にある文字列が、引数に一致すれば真を返す
HexTest()、NumTest()
数値表現に一致にすれば真を返す。数値はプライベートメンバに格納されGetNum()で参照することができる。
引数は先行しなければならない文字列であり、レジスタ変数やメモリ変数を解析するためにある。
VarTest()、AdrsTest()
それぞれ変数(もしくは関数)と、変数アドレスに一致すれば真を返す。
このときの変数名(〃)はプライベートメンバに格納され、GetID()で参照することができる。
ComentSkip()
行末までScanPointerを進める。
Put()
中間コード管理クラスのメンバ。第1引数が中間コード、第2引数が補助情報(整数型)。
RegID()
現われた変数名もしくは関数名を登録する。
GetLC()
現在の行番号を取り出し、行番号を1つ進めます。